
Structure de l'hypertexte UTOPIA
Présentation
Ce document présente la mise en oeuvre de algorithme de recherche de la structure globale d'un hypertexte dans le cas de UTOPIA.
Les unités d'informations
Le document possède 213 unités d'informations que l'on peut classer en 8 catégories.
-
Les unités organisatrices: 'tdm' (unité 1) et 'champs' (unité 2) (table des matières et liste des champs);
-
Les textes d'auteurs (unités 3 à 29) (1);
-
Les citations (unités 30 à 180) ;
-
Les notes (unités 181 à 193) ;
-
L'intro générale : 'intro' (unité 194) et les introductions des parties (unités 195 à 200) ;
-
La bibliographie: 'biblio' (unité 201);
-
La liste des auteurs: 'auteurs' (unité 202);
-
Les champs (familles de mots-clés) (unités 203 à 213) (2).
Ces données sont enregistrées dans 2 matrices, R et D à partir desquelles vont s'effectuer les calculs en particulier la matrice de structure S.
Cas 1 (trunc = 1, coup = 0.01)
Cette analyse se fait à partir de la matrice ST, matrice S tronquée à 0.01 puis dichotomisée.
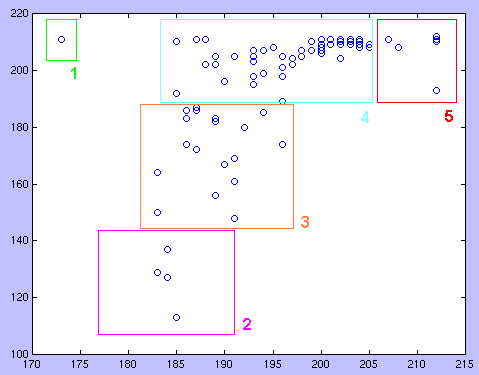
Les points sont organisés de gauche à droite et de bas en haut. Dans la table on note la zone, une brève description et la liste des unités avec leur numéro, leur nom et parfois leurs coordonnées (parenthèses en italique).
Pour information la 'spy' de la matrice ST est :
| Zone | Description | Unités | Remarques |
| Zone 1 | 2 sources "universelles" | 1 tdm (173 211) | |
| Zone 2 | 4 unités centrales | 29 cardinet (185 113) 12 perregaux (184 127) 202 auteurs (183 129) 3 bronckart (184 137) |
Il s'agit de la liste des auteurs et de trois textes d'auteurs (dont la synthèse) qui évoquent plusieurs thèmes. |
| Zone 3 | 18 unités assez centrées | Il s'agit de quatorze auteurs (unités
7, 9, 11, 13-21, 24, 26) et de quatre champs: 205 c_citoyennete 206 c_echange 209 c_innovation 212 c_pluralite |
Les champs les plus centraux sont mis en évidence. |
| Zone 4 | 35 unités qui ont des caractérisriques de sources partielles | On y trouve les dix auteurs restants, l'unité 'champs' (unité 2), six champs, les introductions des parties, quelques notes et citations | Il peut être intéressant de noter que quelques notes et citations se trouvent dans une situation de source. |
| Zone 5 | unités quasi isolées | le champ 'c_interdisciplinarite' (210), la bibliographie (biblio, 201), l'introduction générale (intro, 194) et la grande majorité des notes et des citations | La plupart de ces unités sont isolées 'par construction' (notes et citations). Les trois autres occupent toutefois des positions moins extrêmes (ce qui se notent sur le schéma), les unités 194 et 210 gardent une certaine caractéristique de sources et 201 de puit. |
Cas 2 (trunc = 0)
Pour comparaison, le diagramme obtenu sans opération de "troncage" (et donc sans dichotomisation) paraît moins intéressant.
Les composantes de l'hypertexte
Cette analyse utilise la matrice ST (structure tronquée et dichotomisée) et la symétrise. Ensuite on utilise le fait que dans une composante de l'hypertexte, les unités sont fortement liées entre elles.
L'algorithme utilisé (qui pourrait être remplacé par une analyse cluster standard) procède de la façon suivante.
-
Les unités sont triées par nombre de connexions décroissantes
-
La première unité sert à fabriquer la première composante en ajoutant toutes les unités fortement "corrélées" (coefficient cos).
-
La première unité non corrélées sert de base à la deuxième composante.
-
On teste les unités suivantes par rapport aux deux composantes, et les cas échéant on fabrique de nouvelles composantes.
Cet algorithme est efficace mais il n'est pas symétrique dans le sens où il privilégie les premières composantes formées. Il pourrait être amélioré en choisissant pour chaque unité d'information la composante la plus proche ou en réitérant le procédé. Cela revient à utiliser des algorithmes d'analyse cluster classique (3).
Avec UTOPIA, cet algorithme (avec coupure à 0.3 qui se révèle une valeur "intéressante" laissant peu d'unités isolées tout en gardant plusieurs composantes) fabrique 28 composantes constituées de 2 unités d'information ou plus. 10 unités sont considérées comme isolées: le champ 210, 2 notes et 7 citations. Les 28 composantes sont les suivantes (entre parenthèses le nombre d'unités dans chaque composante):
| Composante | Textes | Champs | Navigation | Autres |
| 1 (34) | 3, 4, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 24, 25, 26, 29 | 205, 206, 208, 209, 212 | liste des auteurs (202) champs (2) table des matières (1) |
1 note 4 citations |
| 2 (33) | 5, 6, 22, 23 | 203, 207, 211, 213 | bibliographie (201) introduction (195, 196, 197, 198, 199) |
19 citations |
| 3 (29) | 27,28 | 204 | introduction (200) | 25 citations |
Les 14 composantes suivantes sont constituées de 5 unités (citations et notes). Il y a encore 5 composantes constituées de 4 unités (citations et notes), puis 5 composantes constituées de 3 unités (citations) et finalement une composante composée de 2 unités: l'introduction générale (unité 194) et une note.
Notes
(1) Les auteurs sont les suivants: 3 bronckart 4 schwaab 5 gigon 6 roller 7 bourquin 8 marc 9 erba 10 matthey 11 abdallah 12 perregaux 13 ludi 14 moore 15 floris 16 gerth 17 dominice 18 cros 19 allal 20 bouvier 21 fleury 22 hainard 23 schurch 24 boillat 25 maspero 26 thevoz 27 florin 28 gredy 29 cardinet (synthèse)
(2) 203 c_acteur 204 c_alterite 205 c_citoyennete 206 c_echange 207 c_europe 208 c_identite 209 c_innovation 210 c_interdisciplinarite 211 c_media 212 c_pluralite 213 c_valeur
(3) Des analyses réalisées avec l'algorithme "k-means" (http://www.cc.gatech.edu/~dellaert/FrankDellaert/Software.html) et l'utilisation des algorithmes de "Statistica" (distance pourcentage de désaccord, méthode de Ward) ne donnent pas de résultats fondamentalement différents et a priori pas plus "intéressants". K-means découpe la première composante en deux parties et regroupe des composantes constituées de citations. Statistica ajoute lie plus fréquemment les notes et citations aux articles dont elles sont issues.