
Analyse cluster et analyse de contenu
Présentation
Le but de cette brève étude est de présenter différents paramètres d'une analyse "cluster" permettant de classer des documents en fonction de leur contenu. Cette analyse se limite à passer en revue les choix (relativement standard) proposés par le logiciel STATISTICA [STA 94].
Jeu de données
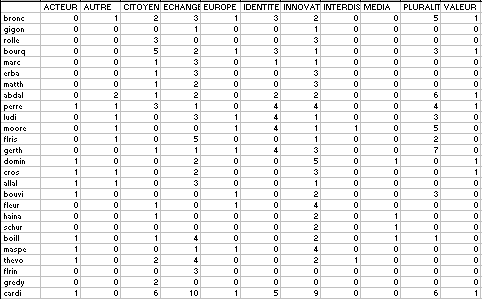
Afin de juger de diverses options sur un matériel connu, le choix du jeu de test s'est porté sur les articles rassemblés dans le document [COR 96]. Ce corpus est consitué de 26 articles, chacun étant indexé par des mots-clés tirés d'un ensemble de 80. Par ailleurs, ces mots-clés sont répartis en 11 familles. Ces données seront utilisées de 4 façons différentes. Les données de base consisteront pour chaque document du nombre de mots-clés qui apparaît dans chacune des 11 familles. Ces données seront désignées par "données pondérées" (tableau 1). Les "données dichotomisées" sont celles du tableau 1 où les valeurs différentes de 0 sont remplacées par 1. Le choix de mettre l'accent sur le dénombrement des familles plutôt que sur les mots-clés provient du fait que le rapport entre nombre de variables et nombre d'observations est le plus équilibré dans ce cas.
Toutefois, on s'intéressera également au dénombrement des mots-clés: on parlera des "données déployées" pour les données signalant pour chaque article la présence d'un mot-clé. Ces données sont dichotomiques. Finalement les "données déployées et pondérées" tiendront compte d'un poids ajouté à chaque mot-clé lié au nombre d'occurences du mot-clé dans le document.
Tableau 1: données pondérées (26 cas et 11 variables)
Choix de la distance
S'agissant de concordance de contenu, la distance donnée par le "pourcent de désaccords" est évidemment la plus adpatée. C'est par exemple celle adoptée par le système ALCESTE [REI sd].
Les distances plus classiques (manhattan, euclidienne) peuvent également convenir, toutefois elles mettent sur un pied d'égalité une différence liée à des nombres d'apparitions différents d'un même mot-clé que la non concordance des mots-clés utilisés. Dans notre cas, elles vont mettre à l'écart le document 'cardi' qui pourtant, s'agissant d'une synthèse, se trouve proche de plusieurs autres documents.
Précisons toutefois que la distance en 1 - |r| (avec r coefficient de corrélation de Pearson) ne saurait convenir dans la mesure où des enregistrement ayant un désaccord complet auront une corrélation élevée (et seront donc proches) sans que les contenus concordent sur aucun point.
Notons par ailleurs que lorsque les données sont dichotomiques, la plupart des distances sont équivalentes. Par la suite toutes les analyses seront effectuées sur la base du "pourcent de désaccords".
Algorithme
L'analyse cluster peut utiliser différentes manières pour calculer la distance entre des groupes et faire intervenir divers algorithmes d'agrégation. Dans la mesure où l'intérêt est d'obtenir des groupes les plus contrastés possibles la méthode du "complete linkage" (la distance entre deux groupes est donnée par celles entre les objets les plus éloignés dans les groupes) et la méthode de Ward (minimisation de la variance intra-groupe) sont les plus adaptées. Cette dernière méthode a tendance à produire de petits groupes. Lapointe & Legendre [LAP 94] présentent cette méthode avec quelques détails.
Résultats
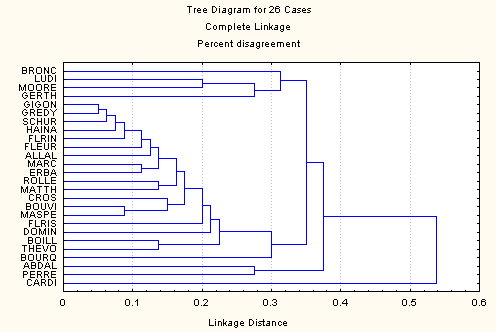
Les figures 1 à 5 représentent les analyses effectuées à partir des différentes variantes du jeu de données à disposition. La figure 1 concerne les données pondérées et la figure 2 les données dichotomisées. Dans les deux cas la méthode utilisée est le "complete linkage". La figure 3 reprend les données pondérées avec la méthode de Ward. Les deux dernières figures concernent les données déployées: dichotomiques dans le cas de la figure 4, pondérées dans le cas de lafigure 5. Dans ces deux cas c'est également le "complete linkage" qui sert de méthode d'agrégation.
L'observation de ces figures permet de faire quelques remarques de portée générale.
Figure 1: données pondérées (11 variables)
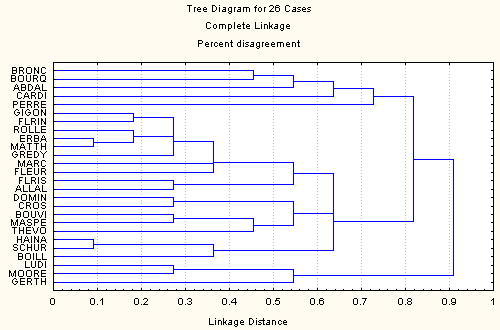
Figure 2: données dichotomisées (11 variables)
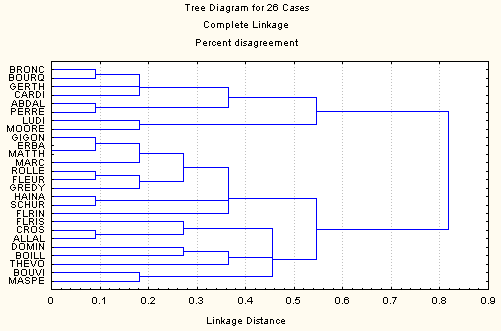
Figure 3: données dichotomisées (11 variables)
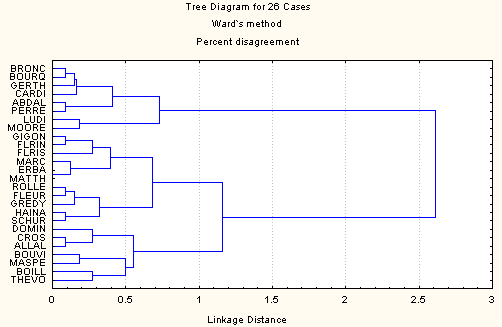
Figure 4 : données déployées (dichotomiques) (80 variables)
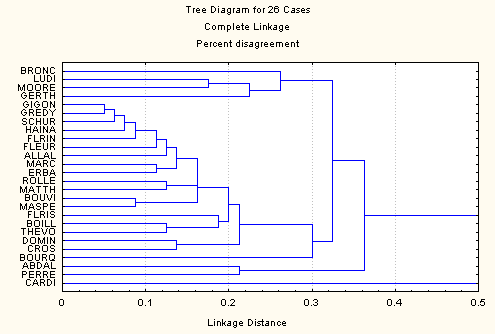
Figure 5: données déployées pondérées (80 variables)
Données dichotomisées versus pondérées
En comparant les figure 1 (données pondérées) et figure 2 (données dichotomisées), on note principalement un plus grand nombre de niveaux dans les distance, comme on pouvait s'y attendre, dans le cas pondéré. Cela implique une décomposition en un plus grand nombre de groupes. Au niveau 0.5, il y a 11 groupes dans le premier cas (avec 4 groupe constitués d'une seule observation) contre 4 dans le second. Par regroupement, la même structure apparaît toutefois avec quelques exceptions. C'est notamment le cas du document 'gerth': isolé et proche des documents 'ludi' et 'moore' dans le premier cas, il change de voisinage dans le second, les désaccords faiblement pondérés avec les deux documents mentionnés prenant une importance accrue dans le cas dichotomisé.
Par contre sur les données déployées, les différences entre le cas dichotomique (figure 4) et les données déployées pondérées (figure 5) sont moindres. Ceci est certainement dû en grande partie à des différences plus faibles au niveau de la pondération, mais aussi au rapport plus élevé entre nombre de variables et nombre d'observations.
"Complete linkage" versus méthode de Ward
Les figures 2 et 3 représentent les mêmes données (dichotomisées) avec, dans le premier cas, la méthode du linkage complet et la méthode de Ward dans le deuxième cas. Les résultats sont très semblables. A niveau égal (0.5 pour la figure 2, 0.6 dans la figure 3 pour tenir compte de l'étendue différente et de l'aspect quadratique de la mesure) on compte 4 groupes dans le premier cas et 5 dans le deuxième avec un niveau de compatibilité élevé.
Données pondérées versus déployées
Ce cas est représenté par les figures 1 (données pondérées) et 4 (déployées dichotomiques). En prenant le niveau 0.6 dans le premier cas (7 groupes) et 0.25 dans le second (6 groupes) on note plusieurs similarités. Toutefois l'organisation des groupes est sensiblement différente. De fait, ce résultat n'est surprenant que si l'on s'attendait à une certaine homogénéité dans l'usage des concepts d'une même famille.
Méthodologie
A un premier niveau, l'analyse cluster peut être utilisée dans un but purement descriptif. En décrivant les groupes (de haut en bas ou de bas en haut selon le cas), on procède ainsi à une sorte d'élicitation d'informations qui pourront être mise en relation avec d'autres résultats et/ou servir à poser des hypothèses. En procédant de la sorte on se trouve souvent face à un "palier" à partir duquel les groupes plus larges (dans le cas bas en haut) ou plus restreints (dans le cas haut en bas) semblent plus difficiles à caractériser. On les nommera les groupes "palier".
Les informations qui ont été analysées par l'analyse cluster peuvent aussi posséder des caractères "externes" non pris en compte dans l'analyse. Par exemple, dans le cas d'analyse de contenu, la provenance du document, l'année, etc.
On affine l'analyse du premier niveau si l'on peut constater une compostion particulière des groupes "palier" en relation avec les caractères externes à l'analyse cluster. A ce niveau il est également possible de procéder à des tests statistiques pour juger de l'aspect aléatoire de la répartition des caractères "externes".
Dans leur article sur la classification des whiskies, Lapointe & Legendre [LAP 94] utilisent une méthode qui permet de définir les groupes "palier" en liaison avec des hypothèses concernant leur relation avec les caractères externes (qui sont ici des répartition géographiques des distilleries).
Conclusion
En définitive, cette brève présentation de l'analyse cluster montre différents choix qui se présentent au chercheur dans le cas d'une analyse de contenu (bien que l'exemple n'est pas une analyse de contenu au sens propre dans la mesure où les mots-clés en nombre limité, sont loin d'épuiser les textes analysés). Des choix simples presque obligés: la distance (en principe "pourcent de désaccords") et l'algorithme d'agrégation ("complete linkage" ou méthode de Ward), et des choix qui vont dépendre des buts du travail: données pondérées ou dichotomisées, méthode de description des groupes, mise en relation avec des caractères externes.
Références
[COR 96] Cornali, I. & Weiss, J. (Ed.) Des utopies ŕ construire. Neuchâtel: Institut romand de recherches et de documentation pédagogique et Lausanne: Loisir et pédagogie, 1996.
[LAP 94] Lapointe, F.-J. & Legendre, P. A classification of pure malt Scotch whiskies. Applied Statistics (1994) 43, 1-22. voir aussi http://adn.biol.umontreal.ca/~numericalecology/reprints/Appl%20Stat%2043,%201994.pdf
[REI sd] Reinert, M. ALCESTE, version 4.0, Analyse de données textuelles. Toulouse: Image
[STA 94] Statistica, volume III: statistics 2. Tulsa OK: Statsoft, 1994.